





Attempting to select a database? Learn about the various kinds of databases and how to choose the best one by using this guide.
Understanding the diverse types of databases and their specific use cases is crucial for selecting the right database for your project. I’ve been working on some detailed course material to help people build real-time data projects, and databases are a big part of that. Based on my research, I wanted to jot down a quick guide on how to select the right type of database for your use case.
Different Types of Databases
To get us started, here’s an overview of various types of databases that you can choose from, with a few popular examples of each one:
Key-Value Stores
Key-Value Stores (a data storage paradigm designed for storing, retrieving, and managing associative arrays, and a data structure more commonly known today as a dictionary or hash table.) are ideal for scenarios requiring rapid read operations and high-performance caching. They typically store data in memory to achieve low latency.
- Memcached: A simple, open-source, distributed memory object caching system primarily used for caching strings. Best suited for lightweight, non-persistent caching needs.
- Redis: An open-source, in-memory data structure store supporting various data types. It offers persistence, replication, and clustering, making it ideal for more complex caching requirements and session storage.
- RocksDB: A high-performance embedded database optimized for multi-core CPUs and fast storage like SSDs. Its use of a log-structured merge-tree (LSM tree) makes it suitable for applications requiring high throughput and efficient storage, such as streaming data processing.
Graph Databases
Excellent for managing highly connected data, graph databases are perfect for applications requiring intensive relationship analysis.
- Neo4j: An ACID-compliant graph database with a high-performance distributed architecture. Ideal for complex relationship and pattern analysis in domains like social networks.
- ArangoDB: A native multi-model database, it offers flexibility for documents, graphs, and key-values. This versatility makes it suitable for applications requiring a combination of these data models.
- Dgraph: A distributed and scalable graph database known for high performance. It’s a good fit for large-scale graph processing, offering a GraphQL-like query language and gRPC API support.
Document Databases
These NoSQL databases store data as JSON documents, suitable for rapid development and applications with evolving data models.
- MongoDB: Known for its ease of development and strong community support, MongoDB is effective in scenarios where flexible schema and rapid iteration are more critical than strict ACID compliance.
- HBase and Cassandra: Both cater to non-structured Big Data. Cassandra is geared towards scenarios requiring high availability with eventual consistency, while HBase offers strong consistency and is better suited for read-heavy applications where data consistency is paramount.
Relational Databases
Traditional transactional databases, often categorized as SQL databases, are ideal for applications with well-defined data models and relatively complex query needs. They typically use Structured Query Language (SQL) as their query language. These may also often be referred to as Online Transaction Processing (OLTP) databases.
- SQLite: A lightweight, self-contained SQL database, best for standalone applications, embedded systems, or small-scale applications not requiring a client/server DBMS.
- PostgreSQL: Offers a robust feature set and strong compliance with SQL standards, making it suitable for a wide range of applications, from simple to complex, particularly where data integrity and extensibility are key.
- Microsoft SQL Server: A proprietary relational database with many different variants for different use cases, ranging from a basic web version for web hosting to a cloud database/data warehouse for massively parallel processing (MPP).
- MySQL: A widely-used open-source SQL database, MySQL is efficient for OLTP with its fast data processing and robustness. It is a go-to choice for web-based applications, e-commerce, and online transaction systems.
- Oracle Database: Known for its scalability and reliability, Oracle Database is a powerful choice for relational databases. It offers advanced features for data warehousing and transaction processing, suitable for enterprise-level applications.
Vector Databases
These specialized databases are tailored for handling vector data and are essential in applications involving complex data types and machine learning.
- Milvus: An open-source vector database designed for AI and ML applications. It excels in handling large-scale vector similarity searches, making it suitable for recommendation systems, image and video retrieval, and natural language processing tasks.
- Pinecone: A scalable vector database service that facilitates efficient similarity search in high-dimensional spaces. Ideal for building real-time applications in AI, such as personalized recommendation engines and content-based retrieval systems.
- Weaviate: An open-source, cloud-native vector database built for scalable and fast vector searches. It’s particularly effective for semantic search applications, combining full-text search with vector search for AI-powered insights.
Real-time Columnar Databases
In the realm of real-time data engineering, columnar databases are crucial for handling complex analytical and ad-hoc queries, particularly in data warehousing and real-time analytics scenarios.
- ClickHouse: A fast open-source column-oriented database management system. ClickHouse is designed for real-time analytics on large datasets and excels in high-speed data insertion and querying, making it ideal for real-time monitoring and reporting.
- Apache Pinot: Tailored for providing ultra-low latency analytics at scale. Apache Pinot is widely used for real-time analytical solutions where rapid data insights and decision-making are critical.
- Apache Druid: Focused on real-time analytics and interactive queries on large datasets. Druid is well-suited for high-performance applications in user-facing analytics, network monitoring, and business intelligence.
- StarRocks: A performance-oriented, real-time analytical processing database. StarRocks is known for its fast query performance and supports complex queries over large datasets, making it suitable for real-time business intelligence.
- Rockset: A real-time indexing database for low-latency search and analytics. Rockset is designed to handle unstructured or semi-structured data, making it appropriate for applications where schema flexibility is needed.
- DuckDB: An in-process SQL OLAP database management system. While not a traditional OLAP database, DuckDB is designed to execute analytical queries efficiently, making it suitable for analytical workloads within data-intensive applications.
- Tinybird: Tinybird is a real-time data platform with a columnar database at its core. Tinybird offers added services on top of database hosting, including managed data source connectors and a rapid API publication layer.
These columnar databases play a pivotal role in real-time data engineering, offering the necessary capabilities to analyze large volumes of data quickly and efficiently. Each of these databases brings unique strengths to the table, making them indispensable tools in scenarios where speed, scalability, and real-time insights are of paramount importance.
OLAP Databases for Warehousing
- Firebolt: Specializes in delivering extreme speed and efficiency on large-scale analytics workloads. Firebolt is optimal for interactive dashboarding, reporting, and ad-hoc analysis of big data.
- Snowflake: A traditional and pervasive Cloud Data Warehouse that can be deployed in multiple cloud environments. Snowflake is geared toward querying large volumes of internal data for business intelligence (BI) and reporting use cases.
- Databricks: Branded as a “Data Lakehouse”, Databricks is a cloud-based platform for big data analytics and machine learning. It is built on Apache Spark and provides an integrated environment for data engineers, data scientists, and analysts to collaborate on analytics and ML projects.
These data warehouses are commonly used for building internal business intelligence views, as they provide an abstracted SQL-based query interface to develop complex analytical views over large amounts of corporate data. That said, these databases are typically not designed for user-facing scenarios requiring low latency reads or high access concurrency.
How do you decide which database to use?
Choosing the right database depends on several factors, including the following:
- Ingestion Patterns
- Read Patterns
- Data Volumes
- Data Mutation Requirements
- Data Structure (Schema)
- Scalability and Performance
- Security and Compliance
- Cost and Resource Management
- Ecosystem and Ease of Use
“Different problems require different solutions… If you have different data, you have a different problem.”
– Mike Acton, Data-Oriented Design and C++, CppCon 2014
Database selection can have significant and lasting implications for your project. The database that you choose will profoundly influence both the present functionality and future scalability of your application. Opting for a database that later proves inadequate can lead to complex, resource-intensive migration efforts, especially if scalability problems are discovered at a production stage.
The first critical understanding in this selection process is that every database comes with its own set of strengths and weaknesses; there’s no universal solution that fits every scenario. If someone tries to tell you their database will solve all your problems with no downsides they are either trying to sell you something or ignorant.
Simplistic comparisons of databases based on popularity, rankings, or implementation languages can be misleading and insufficient. A more effective approach involves a clear definition of your project’s objectives and a thorough understanding of how each database operates. This includes delving into their architectures, data models, query capabilities, scalability prospects, and how they handle data consistency and integrity.
By aligning the unique requirements of your project with the specific characteristics and capabilities of various databases, you can make an informed choice that not only meets your current needs but also supports your long-term goals.
To effectively define your goal and choose the right database for your project, it’s essential to thoroughly answer a series of questions related to your specific use cases. These include but are not limited to the following:
Ingestion Pattern
- Data Size per Write Operation: What is the volume of data you plan to ingest in each operation?
- Ingestion Latency: Are you dealing with streaming data that requires real-time ingestion, or are you using batch processing for your data ingestion?
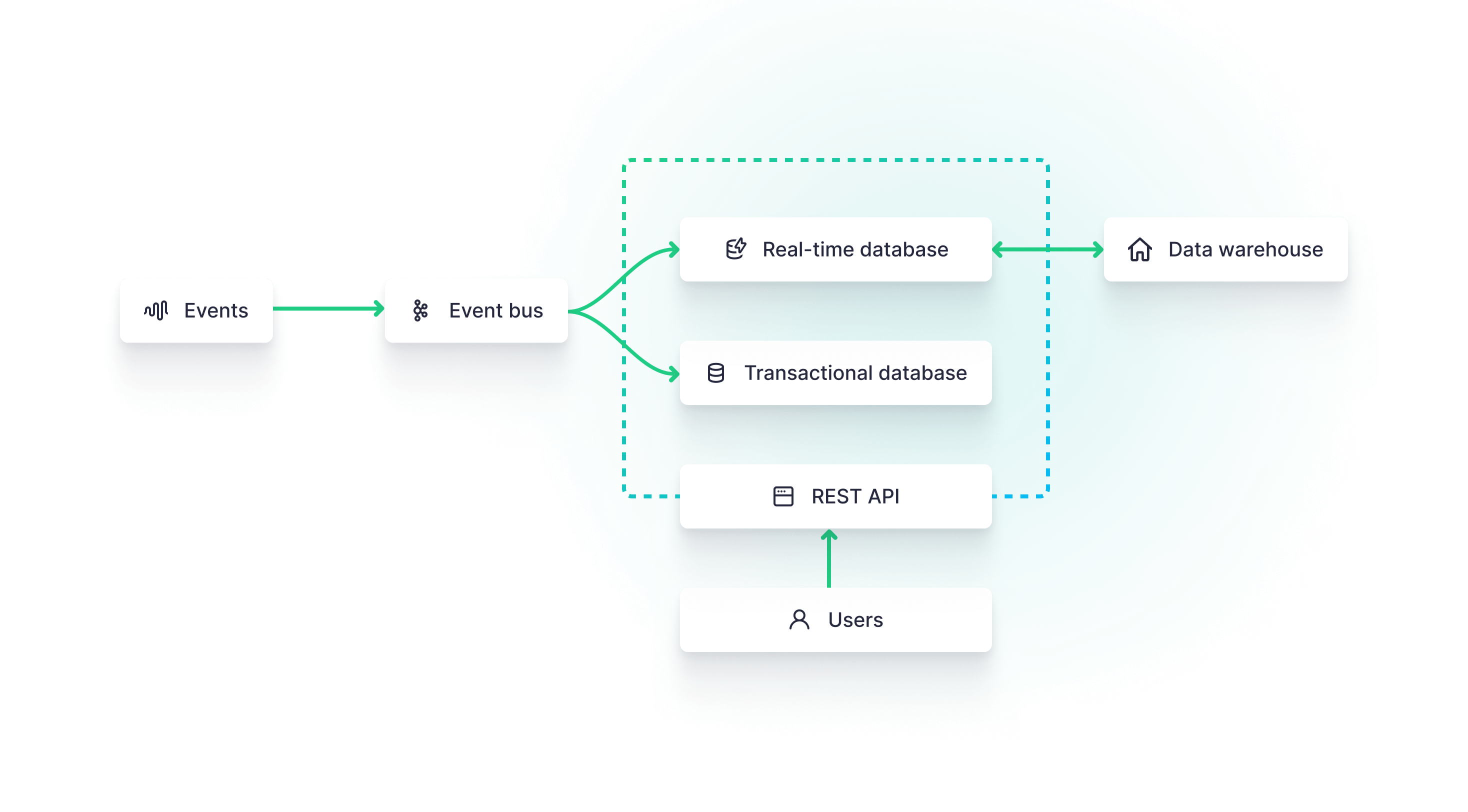
Read Pattern
- Request Latency: How critical is the latency of requests? High request volumes might necessitate tuning your database, scaling, or even switching technologies. Consider the importance of high availability, as not all databases offer this.
- Concurrent Read Operations: How many concurrent read operations do you need to handle?
- Data Consistency Priority: Is data consistency a critical factor in your use case? For instance, in social media platforms, immediate consistency across all users for a new post might not be essential.
- Type of Data Queries: Are your queries more transactional (OLTP), needing specific records, or analytical (OLAP), requiring aggregated metrics on large data sets?
- Query Data Volume: How much data are you querying in each operation? Is it possible to pre-calculate results, or do they need to be computed at query time?
- Query Filters: How many filters are you applying in each query, and to each table?
- Data Joins: Do your queries involve joining information from multiple tables?
- Data Search: Are you performing search operations over your data?

Amount of Data
- Data Storage Volume per Table: What is the expected data volume in each table?
- Data Growth Rate: At what rate do you anticipate your data will grow?
Data Mutation
- Upserts: Is there a need for upsert operations (updating or inserting data)?
- Update Frequency: How frequently will the data be updated?
- Data Deletion: Will you be deleting data? If so, is this a periodic operation?
- Temporary Data Caching: Are you caching data temporarily?
Data Structure (Schema)
- Schema Flexibility: Do you expect your data structure to change frequently?
Scalability and Performance
- Horizontal vs. Vertical Scaling: Will your project (and budget) benefit more from horizontal scaling (adding more machines) or vertical scaling (upgrading existing machine capabilities)?
- Read-Write Ratio: What is the expected ratio of read operations to write operations?
- Performance Under Load: How does the database perform under heavy load or high traffic?
Security and Compliance
- Data Security Needs: What are your requirements for data encryption, both at rest and in transit?
- Compliance Requirements: Are there specific regulatory compliance needs (like GDPR, HIPAA) you need to adhere to?
- Access Control: What level of user access control and permission granularity does the database need to support?
Cost and Resource Management
- Cost-Effectiveness: What is the total cost of ownership, including licensing, hardware, and maintenance?
- Resource Efficiency: How resource-efficient is the database in terms of CPU, memory, and disk usage?
Ecosystem and Ease of Use
- Integration with Existing Systems: How well does the database integrate with your existing technology stack and tools?
- Ecosystem and Community Support: Is there a robust community or ecosystem around the database for support and resources?
- Vendor Lock-in Risks: Are there risks of vendor lock-in, and how easily can you migrate to another database if needed?
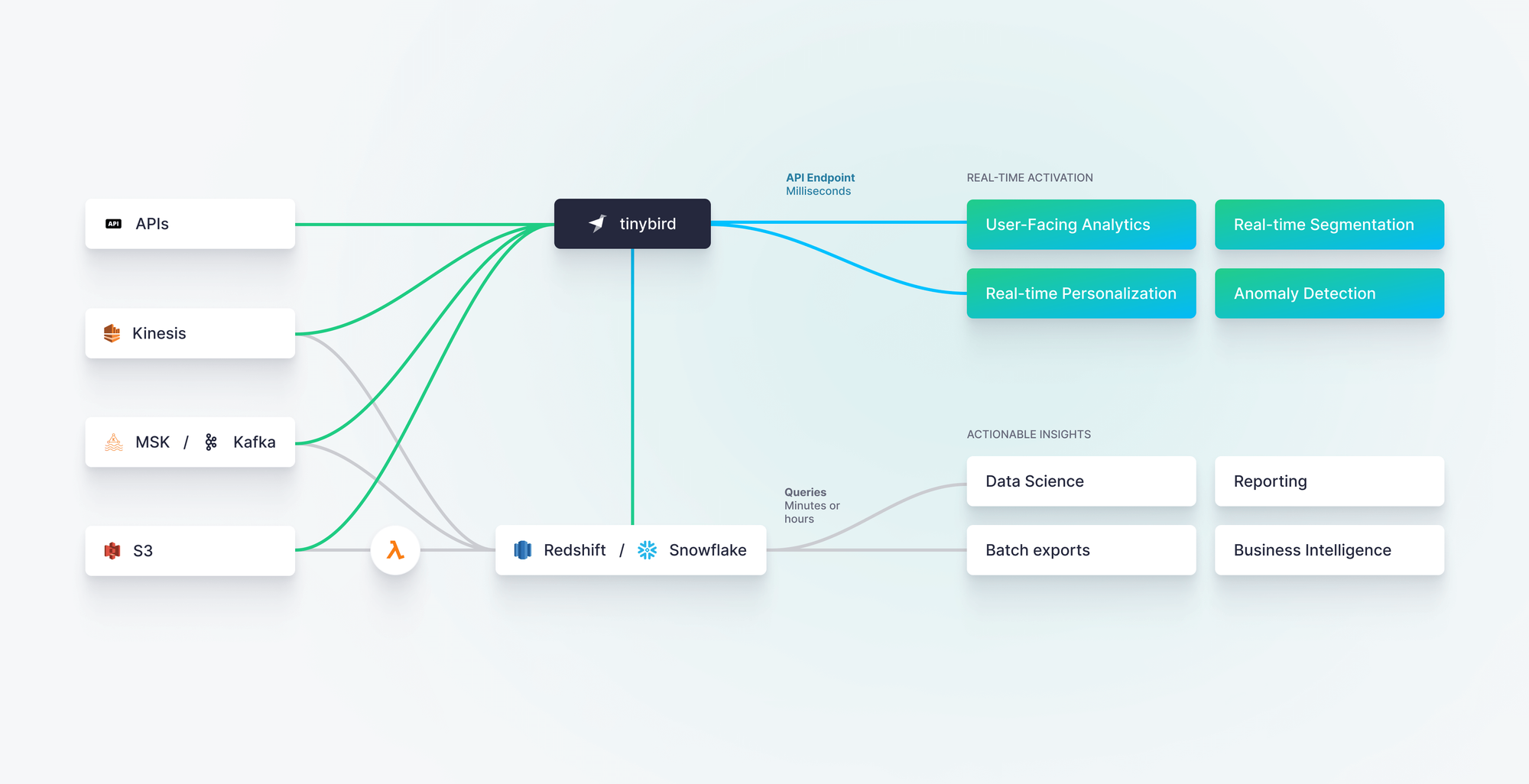
Specific Features and Capabilities
- Real-Time Processing: Does your project require real-time data processing and analytics?
- Data Warehousing Capabilities: If your project involves data warehousing, does the database support large-scale data aggregation and analysis?
- Support for Complex Queries: Can the database efficiently handle complex queries and transactions?
- Data Backup and Disaster Recovery: What are the database’s capabilities for data backup and disaster recovery?
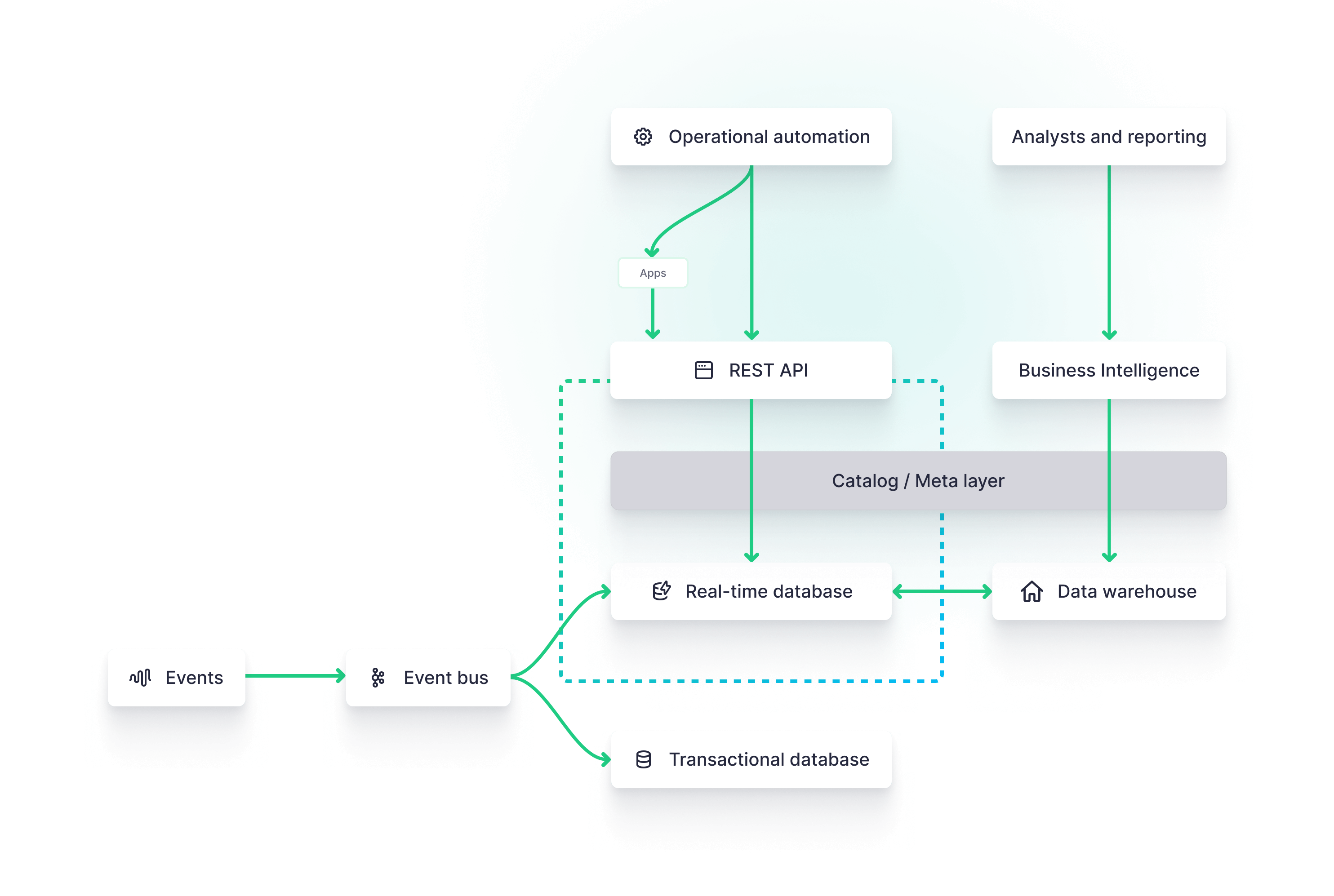
Miscellaneous
- Geographical Distribution: Does the database support the geographical distribution of data, and does it handle issues like latency and data sovereignty effectively?
- The flexibility of Data Models: Does the database support various data models (like document, key-value, graph)?
- Customization and Extensibility: How customizable is the database in terms of features, and does it allow for extensions or custom development?
Other considerations
In addition to these questions, some other things to consider when choosing a database:
ACID Compliance
Not all databases offer strong ACID (Atomicity, Consistency, Isolation, Durability) guarantees. For instance, by default, MongoDB provides ACID compliance at the single document level. Strong ACID compliance is crucial, especially in applications like financial software, where data integrity is non-negotiable. On the other hand, some databases opt for BASE (Basically Available, Soft State, Eventual Consistency) principles, prioritizing flexibility and horizontal scalability. With eventual consistency, the system can remain available even during updates, as each node can respond to read requests without needing the latest data.
Availability
Availability ensures that clients can access the database resources. However, this isn’t always guaranteed due to:
- System Failures: A database cluster with additional nodes can maintain availability during failures.
- High Load: Without adequate scaling, a high request volume can overload the system, increasing latency or causing failures. Ensuring availability often involves setting up a cluster, but this can introduce consistency challenges, as explained in the CAP theorem.
Scalability
Scalability refers to the ability to adapt your infrastructure as demands increase, whether in read/write operations or data volume. It has two dimensions:
- Vertical Scalability: Improving your system’s hardware (CPU, RAM, Disk) to handle more load. While simpler as it avoids complex clustering, no system can scale vertically indefinitely.
- Horizontal Scalability: Adding more machines to your cluster to handle increased load. Technologies like ClickHouse, which scale well vertically, can minimize the need for a large cluster, reducing coordination and replication issues.
Reliability and Maintainability
If your database system faces high loads, specific use cases, or requires fine-tuning, choosing a database with enterprise support could be crucial. High-stakes situations, where temporary failures are costly, necessitate a reliable and maintainable system. Outsourcing your database management can be cost-effective, saving time and simplifying tasks related to reliability, maintainability, and scalability.
Understanding the CAP Theorem
As I said before, there is no silver bullet in the world of databases, and this is best understood through the CAP theorem, a fundamental principle that outlines the trade-offs in distributed systems. The theorem states: “Consistency, Availability, Partition tolerance: pick any two.”
The CAP theorem posits that in a distributed database system, you can only guarantee two out of the following three characteristics at any one time:
- Consistency: Every read receives the most recent write or an error.
- Availability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition Tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
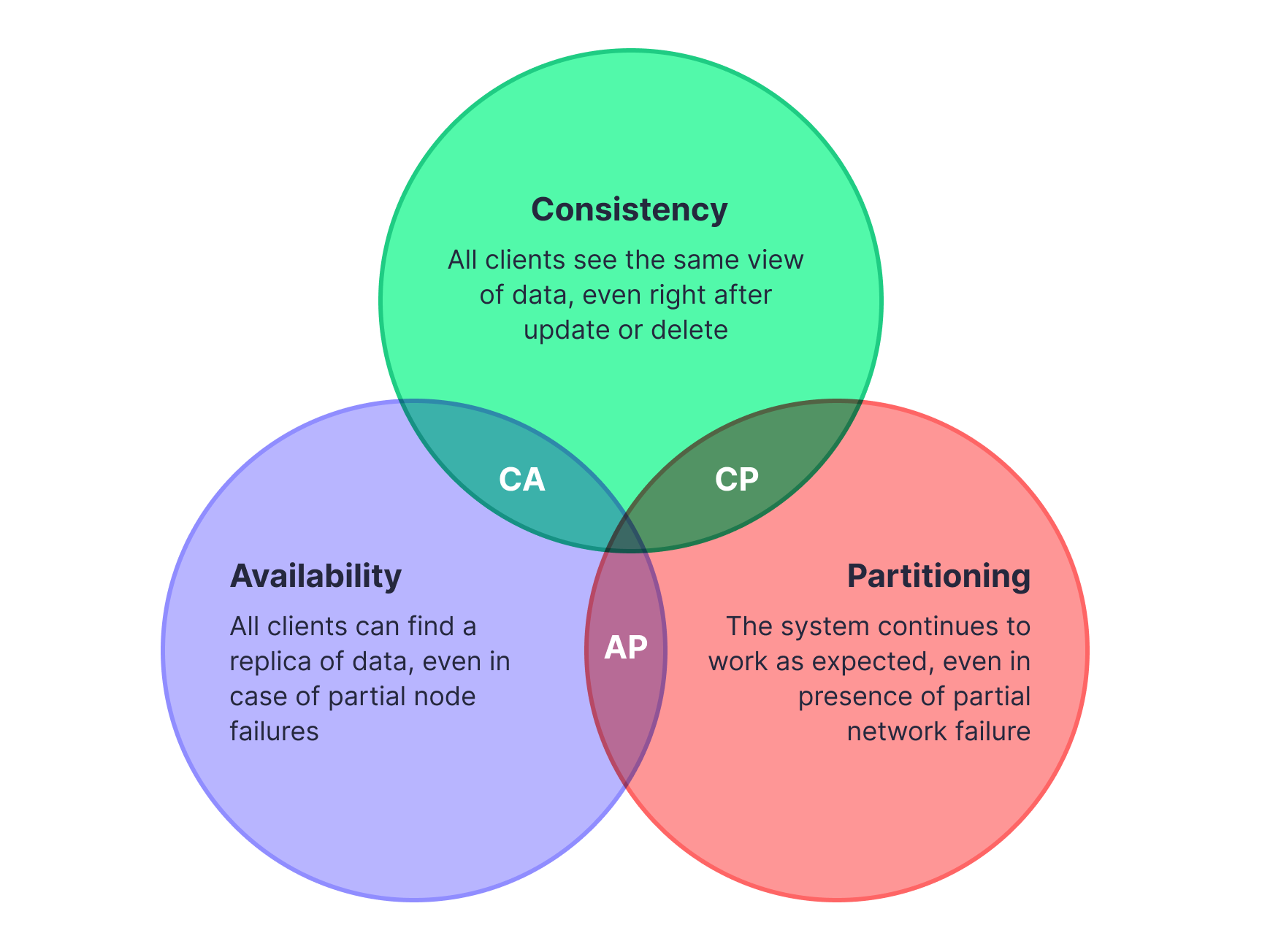
In the absence of a network partition, a system can maintain both consistency and availability. However, the challenge arises when a network partition occurs, which is inevitable in any distributed system. At this point, a system must make a choice:
- Consistency over Availability (CP): When prioritizing consistency, the system ensures that any read operation returns the most recent write. However, this might mean blocking read operations on some nodes until they have the updated value, potentially sacrificing availability.
- Availability over Consistency (AP): Choosing availability implies that the system will always process queries and try to return the most recent available version of the data, even if some nodes are partitioned. This might mean that the data returned is not the most recent, sacrificing consistency.
Why You Can’t Have It All
This trade-off underlines a fundamental truth in database technology: no single database can optimally provide consistency, availability, and partition tolerance simultaneously. Each database makes a conscious choice about which characteristics to prioritize based on its design philosophy and intended use case.
For instance, a financial transaction system might prioritize consistency and partition tolerance to ensure data accuracy, even at the cost of availability. Conversely, a social media platform might prioritize availability and partition tolerance, tolerating some level of data inconsistency to ensure that the platform remains operational at all times.
As a data engineer, understanding the CAP theorem is crucial when choosing a database, as it helps in aligning the database’s characteristics with the specific requirements and constraints of your unique project. Recognizing that compromises are inevitable in distributed systems enables more informed decisions, ensuring that the chosen database best fits your project’s needs now and in the future.



